JDBC vs JPA: Which is Better for Your Application?

Java developers often find themselves working with different technologies to interact with databases efficiently. Two popular approaches for database access in Java applications are JDBC (Java Database Connectivity) and JPA (Java Persistence API).
While both are essential tools for database operations, they differ significantly in their approaches and functionalities. In this article, we will explore the key differences between JDBC and JPA, shedding light on when each is most suitable for Java development projects.
What is JDBC?
JDBC stands for Java Database Connectivity. It's an API (Application Programming Interface) that allows Java programs to connect and interact with databases. Think of it as a bridge between your Java code and the database you're trying to access.
The first version of JDBC was released in 1997, and it has been a part of the Java Standard Edition since version 1.1.
What is JPA?
JPA stands for Java Persistence API. It's a specification for object-relational mapping (ORM) in Java. It allows Java developers to map Java objects to relational database tables.
JPA was first released in 2006 as part of the Java Enterprise Edition 5 (Java EE 5) specification. It has been a part of the Java Standard Edition since version 1.1.
JDBC vs JPA: Key Differences
- Abstraction Level:
- JDBC: It is a low-level API that provides a direct interface to relational databases. Developers need to write SQL queries, handle database connections, and manage result sets manually.
- JPA: It is a higher-level, object-relational mapping (ORM) framework that abstracts away many of the low-level details involved in database interactions. Developers work with Java objects and annotations, and the framework takes care of the underlying database operations.
- Object-Relational Mapping (ORM):
- JDBC: Requires manual mapping of Java objects to database tables and vice versa. Developers need to write SQL queries and handle the translation between the relational model and the object-oriented model.
- JPA: Provides automatic mapping of Java objects to database tables. This mapping is usually done through annotations or XML configurations. JPA implementations, such as Hibernate, handle the translation between Java objects and database tables.
- Performance:
- JDBC: Provides more control over the underlying database operations, allowing for more fine-tuning and optimization. This can lead to better performance in some cases.
- JPA: Provides less control over the underlying database operations, which can lead to suboptimal performance in some cases. However, JPA implementations often provide optimizations and caching mechanisms that can improve performance.
- SQL Handling:
- JDBC: Developers need to write and manage SQL queries explicitly. This gives them more control over the queries, but it also requires more manual effort.
- JPA: Developers can use JPQL (Java Persistence Query Language), which is a higher-level, object-oriented query language. JPQL is similar to SQL but operates on Java objects directly, allowing for more abstraction and less direct manipulation of database-specific syntax.
- Database Connection Management:
- JDBC: Developers need to manage database connections explicitly, including opening, closing, and handling connection pooling. This can be error-prone and may lead to resource leaks if not done correctly.
- JPA: Connection management is abstracted away, and the underlying JPA provider takes care of connection handling. Connection pooling is often handled transparently, simplifying the developer's task.
- Portability:
- JDBC: Code written using JDBC can be more database-specific, as SQL queries may need to be tailored to the specific database dialect.
- JPA: Provides a level of database abstraction, making it easier to switch between different databases with minimal code changes. However, some database-specific optimizations or features may still require database-specific configurations.
Architecture
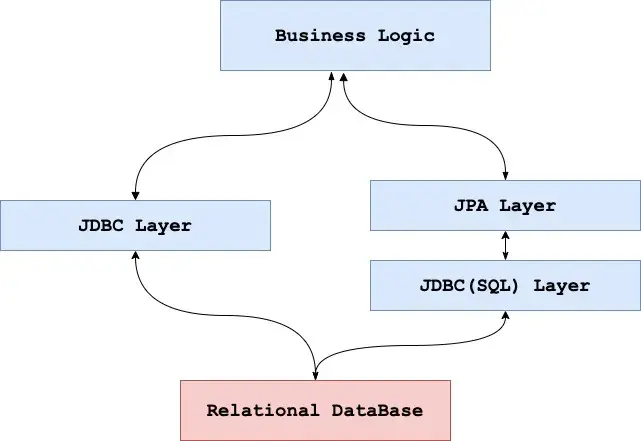
When to Use JDBC
The most suitable scenarios where developers need direct and low-level access to relational databases. JDBC provides a robust and efficient way to interact with databases by allowing developers to write SQL queries directly. This level of control is beneficial in situations where performance optimization, specific database features, or complex queries are crucial. For instance, when dealing with legacy systems, custom data access logic, or performance-critical applications, JDBC is often the preferred choice.
When to Use JPA
Particularly useful when developers prioritize a more object-oriented approach to data persistence. JPA simplifies database interactions by allowing developers to work with Java objects instead of writing raw SQL queries. This abstraction is beneficial in scenarios where the focus is on productivity, code readability, and maintainability.
When to Use Both
Using both JDBC and JPA in a single application can be a pragmatic approach that leverages the strengths of each technology based on specific requirements. In scenarios where fine-grained control over SQL queries is necessary for performance optimization or handling complex database structures, JDBC can be employed. Developers can use JDBC to write custom SQL queries, manage transactions explicitly, and handle database-specific features. Meanwhile, JPA can be employed in areas of the application where a higher level of abstraction is advantageous, such as for standard CRUD ( Create, Read, Update, Delete) operations and mapping Java objects to database entities. This combination allows developers to strike a balance between the flexibility and control offered by JDBC and the productivity and simplicity provided by JPA. It ensures that the application benefits from the efficiency of low-level database interactions when needed, while also taking advantage of the convenience and maintainability offered by an ORM framework for common data access tasks. Integrating both JDBC and JPA in a thoughtful manner enables developers to create robust and efficient applications that meet diverse data access requirements.
The following Github repository contains a Spring Boot application that uses JDBC to interact with a PostgreSQL. database. It also contains a Docker Compose file that can be used to run the application and the database locally.
Code Examples
With the following example of a Customer class, we will demonstrate how to use JDBC and JPA to interact with a database.
- JDBC
public class Customer {
private int id;
private String name;
private int age;
// Constructors
// Getters and Setters
}
import java.sql .*;
import java.util.ArrayList;
public class DataBaseConnection {
private static final String DATABASE_NAME = "CustomerDB";
private static final String URL = "jdbc:mysql://localhost:3306/" + DATABASE_NAME;
private static final String USER = "root"; // set your own username
private static final String PASSWORD = "secret123"; // set your own password
public static Connection getDataBaseConnection() throws SQLException {
try {
Connection databaseConnection = DriverManager.getConnection(URL, USER, PASSWORD);
return databaseConnection;
} catch (SQLException e) {
throw new SQLException("ERROR CONNECTING TO THE DATABASE", e);
}
}
}
public class CustomerDAO {
public static void createTable() throws SQLException {
String createTableQuery = "CREATE TABLE IF NOT EXISTS Customer (id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(255), age INT)";
try (Connection databaseConnection = getDataBaseConnection();
Statement statement = databaseConnection.createStatement()) {
statement.executeUpdate(createTableQuery);
} catch (SQLException e) {
throw new SQLException("ERROR CREATING TABLE", e);
}
}
public static void insertData(String name, int age) throws SQLException {
String insertDataQuery = "INSERT INTO Customer (name, age) VALUES (?, ?)";
try (Connection databaseConnection = getDataBaseConnection();
PreparedStatement preparedStatement = databaseConnection.prepareStatement(insertDataQuery)) {
preparedStatement.setString(1, name);
preparedStatement.setInt(2, age);
preparedStatement.executeUpdate();
} catch (SQLException e) {
throw new SQLException("ERROR INSERTING DATA", e);
}
}
public static ArrayList<Customer> getData() throws SQLException {
String getDataQuery = "SELECT * FROM Customer";
ArrayList<Customer> customers = new ArrayList<>();
try (Connection databaseConnection = getDataBaseConnection();
Statement statement = databaseConnection.createStatement()) {
ResultSet resultSet = statement.executeQuery(getDataQuery);
while (resultSet.next()) {
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
int age = resultSet.getInt("age");
Customer customer = new Customer(id, name, age);
customers.add(customer);
}
} catch (SQLException e) {
throw new SQLException("ERROR GETTING DATA", e);
}
return customers;
}
}
- JPA
First of all we have to set our datasource properties in the application.yml file.
spring:
datasource:
url: jdbc:mysql://localhost:3306/CustomerDB?createDatabaseIfNotExist=true
username: root # set your own user
password: secret123 # set your own password
driver-class-name: com.mysql.cj.jdbc.Driver
jpa:
show-sql: true
hibernate:
ddl-auto: validate
properties:
hibernate:
dialect: org.hibernate.dialect.MySQLDialect
format_sql: true
database: mysql
database-platform: MYSQL
Now we can start creating our Customer class, the CustomerRepository and the CustomerService.
import java.util.List;
import java.util.Optional;
import javax.persistence.*;
@Entity
@Table(name = "Customer")
public class Customer {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private int id;
private String name;
private int age;
// Constructors
// Getters and Setters
}
@Repository
public interface CustomerRepository extends JpaRepository<Customer, Integer> {
}
@Service
public class CustomerService {
@Autowired
private CustomerRepository customerRepository;
public void saveCustomer(Customer customer) {
customerRepository.save(customer);
}
public List<Customer> getAllCustomers() {
return customerRepository.findAll();
}
public Customer getCustomerById(int id) {
return customerRepository.findById(id).orElse(null);
}
public void deleteCustomerById(int id) {
Optional<Customer> customer = customerRepository.findById(id);
if (customer.isPresent()) {
customerRepository.deleteById(id);
} else {
throw new RuntimeException("Customer not found for id :: " + id);
}
}
}
Other Resources
The following video is about Pros and Cons of JDBC and JPA presented by Greg Turnquist.
The following video is an explanation from Dan Vega about the difference between JDBC Client and Spring Data JDBC.
Conclusion
In summary, JDBC is ideal for scenarios requiring low-level database control and performance optimization, while JPA excels in providing a higher-level, object-oriented approach to data persistence, enhancing productivity and maintainability. Combining both JDBC and JPA in a single application allows developers to leverage the strengths of each. JDBC can handle custom and performance-critical tasks, while JPA simplifies standard data access operations. The choice between them or their combination depends on the specific needs of the application, balancing control, and developer productivity.